Research
My research interests include speech recognition by humans and machines, hearing-aid signal processing for speech and music, audio-visual speech processing, machine listening and the application of machine learning to audio processing. I have a number of funded projects in these areas listed below.
Ongoing projects
CHiME-9 ECHI (2025–2027)
Enhancing Conversations to address Hearing Impairment (ECHI)
Despite advancements, modern hearing aids still struggle to consistently isolate and enhance target speech in many dynamic, real-world acoustic settings. However, the emergence of new low-power Deep Neural Network (DNN) chips and other technological breakthroughs is paving the way for more sophisticated signal processing algorithms. These innovations hold immense potential to transform assistive listening technologies.
CHiME-9 ECHI is a new challenge that invites participants to build systems for Enhancing Conversations to address Hearing Impairment (ECHI). We consider signal processing that enables a device such as illustrated below, which will block out unwanted noise but while still allowing the wearer to hear their conversational partners. The task is built around a new dataset consisting of recordings of conversations between four participants seated around a table. During the sessions, a cafeteria environment is simulated using a set of 18 loudspeakers positioned in the recording room. In each session, one participant is using Aria glasses (Project Aria) and another is wearing hearing aid devices with two microphones per ear. The task is to enhance the audio arriving at the device microphones to improve it for the purposes of conversation.

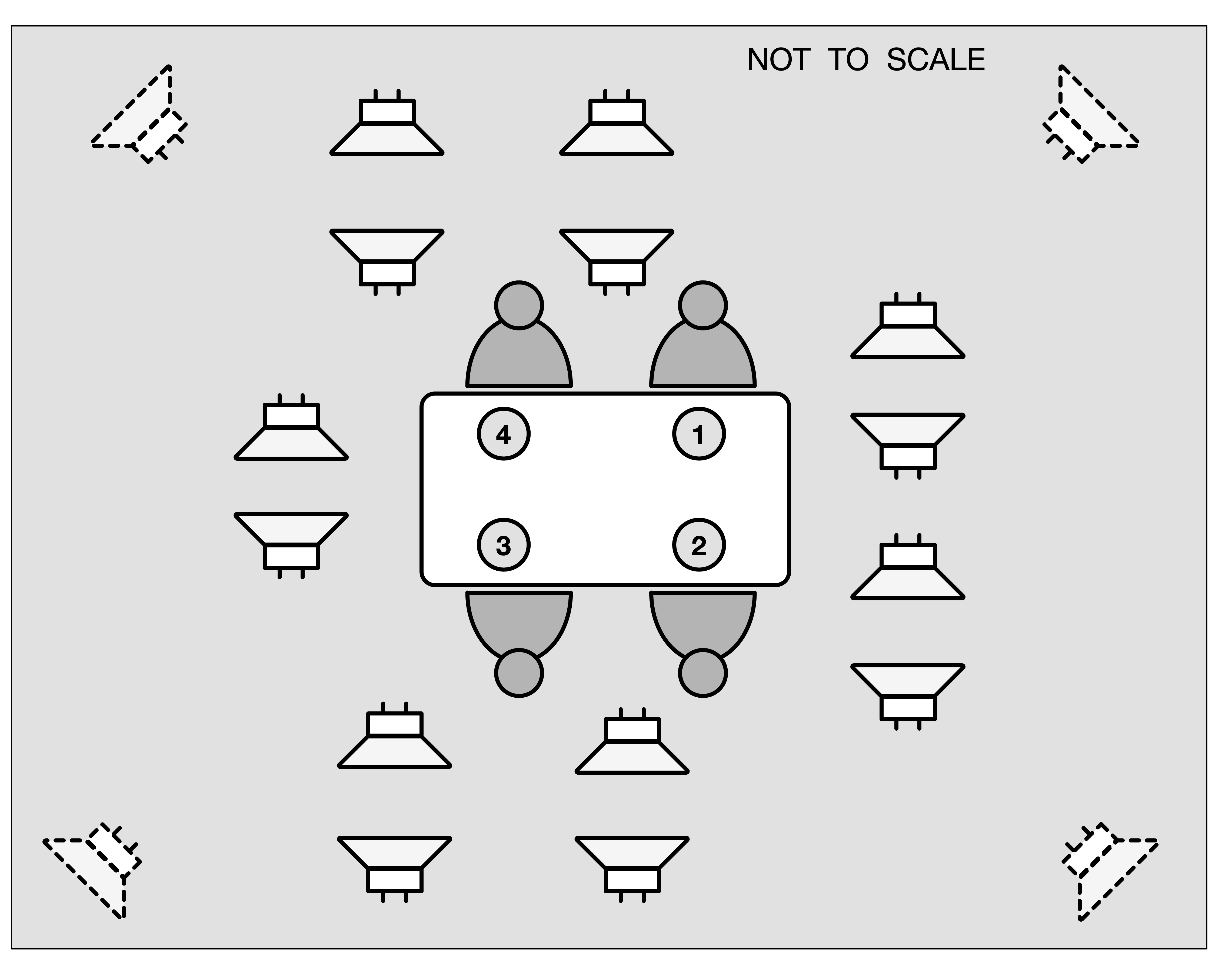
For more details about the dataset and challenge please visit the project website.
Project Website: https://www.chimechallenge.org/current/task2/index
SoundFutures CDT (2024–2032)
EPSRC CDT in Sustainable Sound Futures
The Sustainable Sounds Futures CDT is a leading doctoral training centre, funded by EPSRC in collaboration with the universities of Salford, Sheffield, Bristol, and Southampton. Working with over fifty project partners from industry and government, this initiative delivers an unmatched level of expertise and cutting-edge facilities for Acoustics PhD training.
Cadenza (2022–2027)
Machine Learning Challenges to Revolutionise Music Listening for People with Hearing Loss
Cadenza is a 4.5 year EPSRC project in collaboration with the University of Salford (Acoustics), University of Sheffield (Computer Science), University of Leeds (Music) and University of Nottingham (Medicine) and with the support of the BBC, Google, Logitech, Sonova AG and user engagement via Royal National Institute for the Deaf (RNID).
1 in 6 people in the UK has a hearing loss, and this number will increase as the population ages. Poorer hearing makes music harder to appreciate. Picking out lyrics or melody lines is more difficult; the thrill of a musician creating a barely audible note is lost if the sound is actually inaudible, and music becomes duller as high frequencies disappear. This risks disengagement from music and the loss of the health and wellbeing benefits it creates.
The project will look at personalising music so it works better for those with a hearing loss.
The project will consider:
- Processing and remixing mixing desk feeds for live events or multitrack recordings.
- Processing of stereo recordings in the cloud or on consumer devices.
- Processing of music as picked up by hearing aid microphones.
The project aims to accelerate research in this area by organising a series of signal processing challenges. These challenge will grow a collaborative community who can apply their skills and knowledge to this problem area.
The project will be developing tools, databases and objective models needed to run the challenges. This will lower barriers that currently prevent many researchers from considering hearing loss. Data would include the results of listening tests into how real people perceive audio quality, along with a characterisation of each test subject's hearing ability, because the music processing needs to be personalised. We will develop new objective models to predict how people with a hearing loss perceive audio quality of music. Such data and tools will allow researchers to develop novel algorithms.
Project Website: http://cadenzachallenge.org
SLT CDT (2021–2028)
UKRI CDT in Speech and Language Technologies and their Applications
Speech and Language Technologies (SLTs) are a range of Artificial Intelligence (AI) approaches which allow computer programs or electronic devices to analyse, produce, modify or respond to spoken and written language. They enable natural interaction between people and computers, translation between all human languages, and analysis of speech and text.
Past projects
Clarity (2019–2025)
Challenges to Revolutionise Hearing Device Processing
Clarity is a 5 year EPSRC project in collaboration with the University of Cardiff (Psychology), University of Nottingham (Medicine), University of Salford (Comp Sci) and with the support of the Hearing Industry Research Consortium, Action for Hearing Loss, Amazon and Honda.
The project aims to transform hearing-device research by the introduction of open evaluations ("challenges") similar to those that have been the driving force in many other fields of speech technology. The project will develop the simulation tools, models, databases and listening test protocols needed to facilitate such challenges. We will develop simulators to create different listening scenarios and baseline models to predict how hearing-impaired listeners perceive speech in noise. Data will also include the results of large-scale speech-in-noise listening tests along with a comprehensive characterisation of each test subject's hearing ability. These data and tools will form a test-bed to allow other researchers to develop their own algorithms for hearing aid processing in different listening scenarios. The project will run three challenge cycles with steering from industry partners and the speech and hearing research communities.
Project Website: http://claritychallenge.org
TAPAS (2017–2021)
Training Network on Automatic Processing of PAthological Speech
TAPAS is an H2020 Marie Curie Initial Training Network that will provide research opportunities for 15 PhD students (Early Stage Researchers) to study automatic processing of pathological speech. The network consists of 12 European research institutes and 9 associated partners.
The TAPAS work programme targets three key research problems:
- Detection: We will develop speech processing techniques for early detection of conditions that impact on speech production. The outcomes will be cheap and non-invasive diagnostic tools that provide early warning of the onset of progressive conditions such as Alzheimer's and Parkinson's.
- Therapy: We will use newly-emerging speech processing techniques to produce automated speech therapy tools. These tools will make therapy more accessible and more individually targeted. Better therapy can increase the chances of recovering intelligible speech after traumatic events such a stroke or oral surgery.
- Assisted Living: We will re-design current speech technology so that it works well for people with speech impairments. People with speech impairments often have other co-occurring conditions making them reliant on carers. Speech-driven tools for assisted-living are a way to allow such people to live more independently.
The TAPAS consortium includes clinical practitioners, academic researchers and industrial partners, with expertise spanning speech engineering, linguistics and clinical science. This rich network will train a new generation of 15 researchers, equipping them with the skills and resources necessary for lasting success.
AV-COGHEAR (2015–2018)
Towards visually-driven speech enhancement for cognitively-inspired multi-modal hearing-aid devices
AV-COGHEAR was an EPSRC-funded project that was conducted in collaboration with the University of Stirling. Current commercial hearing aids use a number of sophisticated enhancement techniques to try and improve the quality of speech signals. However, today's best aids fail to work well in many everyday situations. In particular, they fail in busy social situations where there are many competing speech sources; they fail if the speaker is too far from the listener and swamped by noise. We identified an opportunity to solve this problem by building hearing aids that can 'see'.
AV-COGHEAR aimed to develop a new generation of hearing aid technology that extracted speech from noise by using a camera to see what the talker was saying. The goal was that the wearer of the device would be able to focus their hearing on a target talker and the device would filter out competing sound. This ability, which is beyond that of current technology, has the potential to improve the quality of life of the millions suffering from hearing loss (over 10m in the UK alone).
The project brought together researchers with the complementary expertise necessary to make the audio-visual hearing-aid possible. The project combined contrasting approaches to audio-visual speech enhancement that had been developed by the Cognitive Computing group at Stirling and the Speech and Hearing Group at Sheffield. The Stirling approach used the visual signal to filter out noise; whereas the Sheffield approach used the visual signal to fill in 'gaps' in the speech. The MRC Institute of Hearing Research (IHR) provided the expertise needed to evaluate the approach on real hearing loss sufferers. Phonak AG, a leading international hearing aid manufacturer, provided the advice and guidance necessary to maximise potential for industrial impact.
DeepArt (2017–2018)
Deep learning of articulatory-based representations of dysarthric speech
DeepArt is a Google Faculty Award project that is targeting dysarthria, a particular form of disordered speech arising from poor motor-control and a resulting lack of coordination of the articulatory system. At Sheffield, we have demonstrated that using state-of-the-art training techniques developed for mainstream HMM/DNN speech recognition, can raise baseline performance for dysarthric speech recognition.
The DeepArt project will aim to advance the state of the art by conducting research in three key areas:
- articulatory based representations;
- use of synthetic training data and
- novel approaches to DNN based speaker adaptive training.
INSPIRE (2012–2016)
Investigating Speech in Real Environments
INSPIRE is an FP7 Marie Curie Initial Training Network that will provide research opportunities for 13 PhD students (Early Stage Researchers) and 3 postdocs (Experienced Researchers) to study speech communication in real-world conditions. The network consists of 10 European research institutes and 7 associated partners (5 businesses and 2 academic hospitals). The senior researchers in the network are academics in computer science, engineering, psychology, linguistics, hearing science, as well as R&D scientists from leading businesses in acoustics and hearing instruments, and ENT specialists. The scientific goal of INSPIRE is to better understand how people recognise speech in real life under a wide range of conditions that are "non-optimal" relative to the controlled conditions in laboratory experiments, e.g., speech in noise, speech recognition under divided attention.
CHiME (2009–2012)
Computational Hearing in Multisource Environments
CHiME was an EPSRC funded project that aimed to develop a framework for computational hearing in multisource environments. The approach operates by exploiting two levels of processing that combine to simultaneously separate and interpret sound sources (Barker et al. 2010). The first processing level exploits the continuity of sound source properties to clump the acoustic mixture into fragments of energy belonging to individual sources. The second processing level uses statistical models of specific sound sources to separate fragments belonging to the acoustic foreground (i.e. the `attended' source) from fragments belonging to the background.
The project investigated and develop key aspects of the proposed two-level hearing framework:
- statistical tracking models to represent sound source continuity;
- approaches for combining statistical models of foreground and background sound sources
- approximate search techniques for decoding acoustic scenes in real-time
- strategies for learning sound source models directly from noisy audio data
CHiME built a demonstration system simulating a speech-driven home-automation application operating in a noisy domestic environment.
References
@article{barker2010,
author = {Barker, Jon and Ma, Ning and Coy, André and Cooke, Martin},
title = {Speech Fragment Decoding Techniques for Simultaneous Speaker Identification and Speech Recognition},
date = {2010-01},
journaltitle = {Computer Speech \& Language},
shortjournal = {Comput. Speech Lang.},
volume = {24},
number = {1},
pages = {94--111},
issn = {08852308},
doi = {10.1016/j.csl.2008.05.003},
url = {https://linkinghub.elsevier.com/retrieve/pii/S0885230808000314},
urldate = {2025-12-17},
langid = {english},
}S2S (2007–2011)
Sound to Sense
Sound to Sense (S2S) was an EC-funded Marie Curie Research Training Network exploring how humans and computers understand speech. My interest within the network centres on modelling human word recognition in noise (Barker and Cooke 2007; Cooke et al. 2008).
References
@article{barker2007a,
author = {Barker, Jon and Cooke, Martin},
title = {Modelling Speaker Intelligibility in Noise},
date = {2007-05},
journaltitle = {Speech Communication},
shortjournal = {Speech Commun.},
volume = {49},
number = {5},
pages = {402--417},
issn = {01676393},
doi = {10.1016/j.specom.2006.11.003},
url = {https://linkinghub.elsevier.com/retrieve/pii/S0167639306001701},
urldate = {2025-12-17},
langid = {english},
}@article{cooke2008,
author = {Cooke, Martin and Garcia Lecumberri, M. L. and Barker, Jon},
title = {The Foreign Language Cocktail Party Problem: Energetic and Informational Masking Effects in Non-Native Speech Perception},
shorttitle = {The Foreign Language Cocktail Party Problem},
date = {2008-01-01},
journaltitle = {Journal of the Acoustical Society of America},
shortjournal = {J. Acoust. Soc. Am.},
volume = {123},
number = {1},
pages = {414--427},
issn = {0001-4966, 1520-8524},
doi = {10.1121/1.2804952},
url = {https://pubs.aip.org/jasa/article/123/1/414/959109/The-foreign-language-cocktail-party-problem},
urldate = {2025-12-17},
abstract = {Studies comparing native and non-native listener performance on speech perception tasks can distinguish the roles of general auditory and language-independent processes from those involving prior knowledge of a given language. Previous experiments have demonstrated a performance disparity between native and non-native listeners on tasks involving sentence processing in noise. However, the effects of energetic and informational masking have not been explicitly distinguished. Here, English and Spanish listener groups identified keywords in English sentences in quiet and masked by either stationary noise or a competing utterance, conditions known to produce predominantly energetic and informational masking, respectively. In the stationary noise conditions, non-native talkers suffered more from increasing levels of noise for two of the three keywords scored. In the competing talker condition, the performance differential also increased with masker level. A computer model of energetic masking in the competing talker condition ruled out the possibility that the native advantage could be explained wholly by energetic masking. Both groups drew equal benefit from differences in mean F0 between target and masker, suggesting that processes which make use of this cue do not engage language-specific knowledge.},
langid = {english},
}POP (2006–2009)
POP was a three year EC FP6 Specific Targeted Research project that combined auditory scene analysis and vision on robotic platforms. A key achievement in the audio processing was the combination of binaural source localisation techniques (Harding et al. 2006) with a spectro-temporal fragment-based sound source separation component to produce a robust sound source localisation implementation suitable for real time audio motor control (Christensen et al. 2009). We also spent some time on the tricky problems of trying to use acoustic location cues when the ears that are generating the estimates are themselves moving on unpredictable and possibly unknown trajectories (Christensen and Barker 2009).
The demo belows show a custom-made Audio Visual robot called Popeye that was developed as part of the project.
The project also constructed a small corpus of synchronised stereoscopic and binaural recordings (Arnaud et al. 2008) called CAVA which is freely available for download.
References
@inproceedings{arnaud2008,
author = {Arnaud, Elise and Christensen, Heidi and Lu, Yan-Chen and Barker, Jon and Khalidov, Vasil and Hansard, Miles and Holveck, Bertrand and Mathieu, Hervé and Narasimha, Ramya and Taillant, Elise and Forbes, Florence and Horaud, Radu},
title = {The {{CAVA}} Corpus: Synchronised Stereoscopic and Binaural Datasets with Head Movements},
shorttitle = {The {{CAVA}} Corpus},
booktitle = {{{ICMI}} '08 {{Proceedings}} of the 10th International Conference on {{Multimodal}} Interfaces},
date = {2008-10-20},
pages = {109--116},
publisher = {ACM},
location = {Chania Crete Greece},
doi = {10.1145/1452392.1452414},
url = {https://dl.acm.org/doi/10.1145/1452392.1452414},
urldate = {2025-12-17},
eventtitle = {{{ICMI}} '08: {{INTERNATIONAL CONFERENCE ON MULTIMODAL INTERFACES}}},
isbn = {978-1-60558-198-9},
langid = {english},
}@inproceedings{christensen2009c,
author = {Christensen, Heidi and Barker, Jon},
title = {Using Location Cues to Track Speaker Changes from Mobile, Binaural Microphones},
booktitle = {Proceedings of the 10th {{Annual Conference}} of the {{International Speech Communication Association}} ({{Interspeech}} 2009)},
date = {2009-09-06},
pages = {140--143},
publisher = {ISCA},
location = {Brighton, UK},
doi = {10.21437/Interspeech.2009-52},
url = {https://www.isca-archive.org/interspeech_2009/christensen09_interspeech.html},
urldate = {2025-12-17},
eventtitle = {Interspeech 2009},
langid = {english},
}@inproceedings{christensen2009,
author = {Christensen, Heidi and Ma, Ning and Wrigley, Stuart N. and Barker, Jon},
title = {A Speech Fragment Approach to Localising Multiple Speakers in Reverberant Environments},
booktitle = {Proceedings of the 2009 {{IEEE International Conference}} on {{Acoustics}}, {{Speech}} and {{Signal Processing}} ({{ICASSP}})},
date = {2009-04},
pages = {4593--4596},
publisher = {IEEE},
location = {Taipei, Taiwan},
doi = {10.1109/ICASSP.2009.4960653},
url = {http://ieeexplore.ieee.org/document/4960653/},
urldate = {2025-12-17},
eventtitle = {{{ICASSP}} 2009 - 2009 {{IEEE International Conference}} on {{Acoustics}}, {{Speech}} and {{Signal Processing}}},
isbn = {978-1-4244-2353-8},
langid = {english},
}@article{harding2006,
author = {Harding, Sue and Barker, Jon P. and Brown, Guy J.},
title = {Mask Estimation for Missing Data Speech Recognition Based on Statistics of Binaural Interaction},
date = {2006-01},
journaltitle = {IEEE Transactions on Audio, Speech, and Language Processing},
shortjournal = {IEEE Audio, Speech, Language Process.},
volume = {14},
number = {1},
pages = {58--67},
issn = {1558-7916},
doi = {10.1109/TSA.2005.860354},
url = {http://ieeexplore.ieee.org/document/1561264/},
urldate = {2025-12-17},
langid = {english},
}AVASR (2004–2007)
Audio visual speech recognition in the presence of multiple speakers
This was an EPSRC project which looked at audio-visual speech recognition is 'cocktail party' conditions -- i.e. when there are several people speaking simultaneously. The work first showed that standard multistream AVASR approaches are not appropriate in these conditions (Shao and Barker 2008). The project then developed an audio-visual extension of the speech fragment decoding approach (Barker and Shao 2009), that, like humans, is able to exploit the visual signal not only for its phonetic content but also in its role as a cue for acoustic source separation. The latter role is also observed in human audio-visual speech processing where the visual speech input can produce an 'informational masking release' leading to increased intelligibility even in conditions where the visual signal provides little or no useful phonetic content.
The project also partially funded the collection of the AV Grid corpus (Cooke et al. 2006) which is available for download either from the University of Sheffield or from from Zenodo.
Demos of a face marker tracking tool (Barker 2005) that was built at the start of the project can be found here.
References
@inproceedings{barker2005b,
author = {Barker, Jon P.},
title = {Tracking Facial Markers with an Adaptive Marker Collocation Model},
booktitle = {Proceedings of the 2005 {{IEEE International Conference}} on {{Acoustics}}, {{Speech}} and {{Signal Processing}} ({{ICASSP}})},
date = {2005},
volume = {2},
pages = {665--668},
publisher = {IEEE},
location = {Philadelphia, Pennsylvania, USA},
doi = {10.1109/ICASSP.2005.1415492},
url = {http://ieeexplore.ieee.org/document/1415492/},
urldate = {2025-12-17},
eventtitle = {({{ICASSP}} '05). {{IEEE International Conference}} on {{Acoustics}}, {{Speech}}, and {{Signal Processing}}, 2005.},
isbn = {978-0-7803-8874-1},
langid = {english},
}@article{barker2009,
author = {Barker, Jon P. and Shao, Xu},
title = {Energetic and Informational Masking Effects in an Audio-Visual Speech Recognition System.},
date = {2009-03},
journaltitle = {IEEE Transactions on Audio, Speech and Language Processing},
volume = {17},
number = {3},
pages = {446--458},
doi = {10.1109/TASL.2008.2011534},
}@article{cooke2006,
author = {Cooke, Martin and Barker, Jon and Cunningham, Stuart and Shao, Xu},
title = {An Audio-Visual Corpus for Speech Perception and Automatic Speech Recognition},
date = {2006-11-01},
journaltitle = {Journal of the Acoustical Society of America},
shortjournal = {J. Acoust. Soc. Am.},
volume = {120},
number = {5},
pages = {2421--2424},
issn = {0001-4966, 1520-8524},
doi = {10.1121/1.2229005},
url = {https://pubs.aip.org/jasa/article/120/5/2421/934379/An-audio-visual-corpus-for-speech-perception-and},
urldate = {2025-12-17},
abstract = {An audio-visual corpus has been collected to support the use of common material in speech perception and automatic speech recognition studies. The corpus consists of high-quality audio and video recordings of 1000 sentences spoken by each of 34 talkers. Sentences are simple, syntactically identical phrases such as “place green at B 4 now.” Intelligibility tests using the audio signals suggest that the material is easily identifiable in quiet and low levels of stationary noise. The annotated corpus is available on the web for research use.},
langid = {english},
}@article{shao2008,
author = {Shao, Xu and Barker, Jon},
title = {Stream Weight Estimation for Multistream Audio–Visual Speech Recognition in a Multispeaker Environment},
date = {2008-04},
journaltitle = {Speech Communication},
shortjournal = {Speech Commun.},
volume = {50},
number = {4},
pages = {337--353},
issn = {01676393},
doi = {10.1016/j.specom.2007.11.002},
url = {https://linkinghub.elsevier.com/retrieve/pii/S0167639307001860},
urldate = {2025-12-17},
langid = {english},
}Multisource (2002–2005)
Multisource decoding for speech in the presence of other sound sources
This was an EPSRC funded project that aimed "to generalise Automatic Speech Recognition decoding algorithms for natural listening conditions, where the speech to be recognised is one of many sound sources which change unpredictably in space and time". During this project we continued the development of the Speech Fragment Decoding approach (that was begun towards the end of the RESPITE project) leading to a theoretical framework published in (Barker et al. 2005). Also during this time we experimented with applications of the missing data approach to binaural conditions (Harding et al. 2006) and as a technique for handling reverberation (Palomäki et al. 2004).
References
@article{barker2005,
author = {Barker, Jon P. and Cooke, Martin P. and Ellis, D.P.W.},
title = {Decoding Speech in the Presence of Other Sources},
date = {2005-01},
journaltitle = {Speech Communication},
shortjournal = {Speech Commun.},
volume = {45},
number = {1},
pages = {5--25},
issn = {01676393},
doi = {10.1016/j.specom.2004.05.002},
url = {https://linkinghub.elsevier.com/retrieve/pii/S0167639304000615},
urldate = {2025-12-17},
langid = {english},
}@article{harding2006,
author = {Harding, Sue and Barker, Jon P. and Brown, Guy J.},
title = {Mask Estimation for Missing Data Speech Recognition Based on Statistics of Binaural Interaction},
date = {2006-01},
journaltitle = {IEEE Transactions on Audio, Speech, and Language Processing},
shortjournal = {IEEE Audio, Speech, Language Process.},
volume = {14},
number = {1},
pages = {58--67},
issn = {1558-7916},
doi = {10.1109/TSA.2005.860354},
url = {http://ieeexplore.ieee.org/document/1561264/},
urldate = {2025-12-17},
langid = {english},
}@article{palomaki2004,
author = {Palomäki, Kalle J and Brown, Guy J and Barker, Jon P},
title = {Techniques for Handling Convolutional Distortion with 'missing Data' Automatic Speech Recognition},
date = {2004-06},
journaltitle = {Speech Communication},
shortjournal = {Speech Commun.},
volume = {43},
number = {1--2},
pages = {123--142},
issn = {01676393},
doi = {10.1016/j.specom.2004.02.005},
url = {https://linkinghub.elsevier.com/retrieve/pii/S0167639304000238},
urldate = {2025-12-17},
langid = {english},
}RESPITE (1999–2002)
Recognition of Speech by Partial Information TEchniques
Before taking up a lectureship I spent three years as a postdoc working on the EC ESPRIT funded RESPITE project. The project focused on researching and developing new methodologies for robust Automatic Speech Recognition based on missing-data theory and multiple classification streams. During the project soft missing data techniques were developed (Barker et al. 2000) and competitively evaluated on the Aurora speech recognition task (Barker et al. 2001). At the same time, and in collaboration with Martin Cooke and Dan Ellis, the initial ideas for what became Speech Fragment Decoding were formulated (Barker et al. 2000). A separate collaboration with Andrew Morris and Herve Bourlard lead to a generalisation of the missing data approach ('soft data modelling') that is closely related to what is now know as 'uncertainty decoding' (Morris et al. 2001).
It was also during the RESPITE project that the CASA Toolkit (CTK) was developed. CTK aimed to provide a flexible and extensible software framework for the development and testing of Computational Auditory Scene Analysis (CASA) systems. The toolkit allowed auditory-based signal processing front-ends to be developed using a graphical interface (somewhat similar to Simulink). The toolkit also contained implementations of the various missing data speech recognition algorithms that have been developed at Sheffield. The front-end processing code has largely been made redundant by MATLAB, however we still use the CTK missing data and speech fragment speech recognition code.
References
@inproceedings{barker2000,
author = {Barker, Jon and Cooke, Martin and Ellis, Daniel P. W.},
title = {Decoding Speech in the Presence of Other Sound Sources},
booktitle = {Proceedings of the {{International Conference}} on {{Spoken Language Processing}}},
date = {2000-10-16},
pages = {vol. 4, 270-273-0},
publisher = {ISCA},
location = {Beijing, China},
doi = {10.21437/ICSLP.2000-803},
url = {https://www.isca-archive.org/icslp_2000/barker00b_icslp.html},
urldate = {2025-12-17},
eventtitle = {6th {{International Conference}} on {{Spoken Language Processing}} ({{ICSLP}} 2000)},
langid = {english},
}@inproceedings{barker2001b,
author = {Barker, Jon and Cooke, Martin and Green, Phil},
title = {Robust {{ASR}} Based on Clean Speech Models: An Evaluation of Missing Data Techniques for Connected Digit Recognition in Noise},
shorttitle = {Robust {{ASR}} Based on Clean Speech Models},
booktitle = {Proceedings of the 7th {{European Conference}} on {{Speech Communication}} and {{Technology}}, 2nd {{INTERSPEECH Event}}, {{Eurospeech}} 2001},
date = {2001-09-03},
pages = {213--217},
publisher = {ISCA},
location = {Aalborg, Denmark},
doi = {10.21437/Eurospeech.2001-76},
url = {https://www.isca-archive.org/eurospeech_2001/barker01_eurospeech.html},
urldate = {2025-12-17},
eventtitle = {7th {{European Conference}} on {{Speech Communication}} and {{Technology}} ({{Eurospeech}} 2001)},
langid = {english},
}@inproceedings{morris2001,
author = {Morris, Ac and Barker, J and Bourlard, H},
title = {From Missing Data to Maybe Useful Data: Soft Data Modelling for Noise Robust Asr},
shorttitle = {From Missing Data to Maybe Useful Data},
booktitle = {Proceedings of the {{Workshop}} on {{Innovation}} in {{Speech Processing}} ({{WISP}} 2001)},
date = {2001},
publisher = {Institute of Acoustics},
location = {Stratford-upon-Avon, UK},
doi = {10.25144/18432},
url = {https://www.ioa.org.uk/catalogue/paper/missing-data-maybe-useful-data-soft-data-modelling-noise-robust-asr},
urldate = {2025-12-17},
eventtitle = {Workshop on {{Innovation}} in {{Speech Processing}} ({{WISP}}) 2001},
langid = {english},
}SPHEAR (1998–1999)
Speech Hearing and Recognition
Prior to RESPITE, I spent a year at ICP in Grenoble (now known as Gipsa-Lab) as a Postdoc on SPHEAR, an EC Training and Mobility of Researchers network. The twin goals of the network were to achieve better understanding of auditory information processing and to deploy this understanding in automatic speech recognition for adverse conditions. During the year I worked with Frédéric Berthommier and Jean-Luc Schwarz studying the relation between audio and visual aspects of the speech signal (Barker and Berthommier 1999a, 1999b; Barker et al. 1998).
References
@inproceedings{barker1999,
author = {Barker, Jon P. and Berthommier, Frederic},
title = {Estimation of Speech Acoustics from Visual Speech Features: A Comparison of Linear and Non-Linear Models},
shorttitle = {Estimation of Speech Acoustics from Visual Speech Features},
booktitle = {Proceedings of the {{ISCA Workshop}} on {{Auditory-Visual Speech Processing}} ({{AVSP}}) '99},
date = {1999},
pages = {paper 19},
location = {University of California, Santa Cruz},
url = {https://www.isca-archive.org/avsp_1999/barker99_avsp.html},
eventtitle = {Proc. {{AVSP}} 1999},
langid = {english},
}@inproceedings{barker1999a,
author = {Barker, Jon P. and Berthommier, Frederic},
title = {Evidence of Correlation between Acoustic and Visual Features of Speech},
booktitle = {Proc. {{ICPhS}} '99},
date = {1999-08},
location = {San Francisco},
url = {https://www.internationalphoneticassociation.org/icphs-proceedings/ICPhS1999/papers/p14_0199.pdf},
langid = {english},
}@inproceedings{barker1998a,
author = {Barker, Jon P. and Berthommier, Frederic and Schwartz, Jean-Luc},
title = {Is Primitive {{AV}} Coherence an Aid to Segment the Scene?},
booktitle = {Proceedings of the {{ISCA Workshop}} on {{Auditory-Visual Speech Processing}} ({{AVSP}}) '98},
date = {1998},
pages = {103--108},
location = {Sydney, Australia},
url = {https://www.isca-archive.org/avsp_1998/barker98_avsp.html},
eventtitle = {Proc. {{AVSP}} 1998},
langid = {english},
}SPRACH (1997–1998)
Speech Recognition Algorithms for Connectionist Hybrids
SPRACH was an ESPRIT Long Term Research Programme project running from 1995 to 1998 which I was employed on for a brief six month stint while completing my PhD thesis. I had some fun doing some audio segmentation work with Steve Renals (then at Sheffield). The SPRACH project was performing speech recognition on radio broadcasts using what was then called a `hybrid MLP/HMM' recogniser, i.e. an MLP is used to estimate phone posteriors which are then converted in likelihoods and decoded using an HMM in the usual manner. The audio-segmnetation work attempted to use features derived from the phone posteriors to segment the audio into regions that would be worth decoding (i.e. likely to give good ASR results) and regions that would not (i.e. either non-speech or very noisy speech regions) (Barker et al. 1998).
References
@inproceedings{barker1998,
author = {Barker, Jon and Williams, Gethin and Renals, Steve},
title = {Acoustic Confidence Measures for Segmenting Broadcast News},
booktitle = {Proc. {{ICSLP}} '98},
date = {1998-11-30},
pages = {paper 0643-0},
publisher = {ISCA},
location = {Sydney, Australia},
doi = {10.21437/ICSLP.1998-605},
url = {https://www.isca-archive.org/icslp_1998/barker98_icslp.html},
urldate = {2025-12-17},
eventtitle = {5th {{International Conference}} on {{Spoken Language Processing}} ({{ICSLP}} 1998)},
langid = {english},
}PhD Thesis (1994–1997)
Auditory organisation and speech perception
My thesis work (Barker et al. 1998; Barker and Cooke
1997), supervised by
<a href="http://www.laslab.org/martin">Martin
Cooke</a>, was inspired by a paper
(<a href="http://www.ncbi.nlm.nih.gov/pubmed/8121955">Remez et
al., 1994</a>), that had been recently published at the time,
which employed experiments using a particular synthetic analogue of
natural speech, known as
'<a href="http://www.haskins.yale.edu/research/sws.html">sine
wave speech</a>' (SWS), to apparently invalidate the
<a href="http://en.wikipedia.org/wiki/Auditory_scene_analysis">auditory
scene analysis</a> (ASA) account of perception-- at least, in
as far as it showed that ASA did not seem to account for the perceptual
organisation of speech signals. This was a big deal at the time because
it raised doubt about whether computational models of auditory scene
analysis (CASA) were worth pursuing as a technology for robust speech
processing. The thesis confirmed Remez' observation that listeners can
be prompted to hear SWS utterances as coherent speech percepts despite
SWS seemingly lacking the acoustic 'grouping' cues that were supposedly
essential for coherency under the ASA account. However, the thesis went
on to demonstrate that the coherency of the sine wave speech percept is
fragile -- e.g. listeners are not able to attend to individual SWS
utterances when pairs SWS utterances are presented simultaneously (the
'sine wave speech cocktail party' (Barker and Cooke
1999)). Computational modelling studies indicated
that, in fact, the fragility of SWS and the limited intelligibility of
simultaneous sine wave speakers could be described fairly well by
CASA-type models that combine bottom-up acoustic grouping rules and
top-down models.
References
@inproceedings{barker1997,
author = {Barker, Jon P. and Cooke, Martin P.},
title = {Is the Sine-Wave Cocktail Party Worth Attending?},
booktitle = {Proceedings of the 2nd {{Workshop}} on {{Computational Auditory}}, {{Scene Analysis}}},
date = {1997},
publisher = {Int. Joint Conf. Artificial Intelligence},
location = {Nagoya, Japan},
langid = {english},
}@article{barker1999b,
author = {Barker, Jon and Cooke, Martin},
title = {Is the Sine-Wave Speech Cocktail Party Worth Attending?},
date = {1999-04},
journaltitle = {Speech Communication},
shortjournal = {Speech Commun.},
volume = {27},
number = {3--4},
pages = {159--174},
issn = {01676393},
doi = {10.1016/S0167-6393(98)00081-8},
url = {https://linkinghub.elsevier.com/retrieve/pii/S0167639398000818},
urldate = {2025-12-17},
langid = {english},
}@inproceedings{barker1998,
author = {Barker, Jon and Williams, Gethin and Renals, Steve},
title = {Acoustic Confidence Measures for Segmenting Broadcast News},
booktitle = {Proc. {{ICSLP}} '98},
date = {1998-11-30},
pages = {paper 0643-0},
publisher = {ISCA},
location = {Sydney, Australia},
doi = {10.21437/ICSLP.1998-605},
url = {https://www.isca-archive.org/icslp_1998/barker98_icslp.html},
urldate = {2025-12-17},
eventtitle = {5th {{International Conference}} on {{Spoken Language Processing}} ({{ICSLP}} 1998)},
langid = {english},
}